Chapter 4 Collecting and Editing Data
Written by Ira Sutherland and Paul Pickell
Our ability to answer spatial questions or produce a map or other visuals relies, in part, on first finding the right data for the question. We often spend much of our time finding, collecting, and editing data, yet the critical activity of finding data is often left as something that practitioners are assumed to pick up along the way. This chapter addresses that gap by first introducing a range of possible data sources along with some theory, tips, and strategies to access them. We also address some common instances when data do not yet exist, and so we must create them. This chapter may be particularly useful for students and practitioners starting out on their spatial research projects, and for anyone interested in the rapidly changing data universe.
- Become familiar with a wide range of spatial datasets and strategies to access them
- Identify several sources of historical spatial data, including historical maps and aerial photos, and the steps required to analyze them
- Recognize good practices and strategies for writing and reading metadata
Key Terms
Aerial Photography, Area of Interest, Census, Data Repository, Data Request, Georeferencing, Graticule, Natural Resource Administrative Data, Historical Collections, Open Data, Orthophoto, Relief Displacement, Rubbersheeting, Spatial Panel Data
4.1 Open Data
Data are becoming increasingly easy to access thanks to the open data movement. The concept of open data suggests that governmental data should be available to anyone to use and, if desired, redistribute in any form without any copyright restriction or with minimal restrictions such as providing recognition (Kassen 2013).
Until recently, most government data were simply unavailable or could only be accessed by request or by paying the data provider. Countries around the world are moving to an open data model. For example, Britain is opening up its national geographic database (housed as the ‘Ordnance Survey’). The United States (US) has moved its data housed within the US Geological Survey into the public domain (USGS n.d.). Canada has signed a Directive on Open Government, which promotes the proactive and ongoing release of government information. The province of British Columbia (BC) has just released all government LiDAR data under an open government license and many provinces and municipalities release data under similar licenses. Canada is also signatory of the Treaty of Open Skies, which is an international effort that encourages the sharing of aerial imagery to promote openness and transparency of each signatory nation’s military forces and activities. Despite the tremendous momentum towards open data, many datasets are not yet fully open. The tips and strategies below will help locate both open and not-so-open datasets.
4.2 Finding Data
Here we introduce a network model to set a framework for finding data. Imagine that nearly all the data and information in the world is connected in some way through networks of information, composed of individuals, libraries, and institutions. The internet is an important component in this network, one we all use every day to answer questions. For example, me might ask Google: what is the best lake in Canada to plan a summer holiday? A common answer returned is Lake Louise, Alberta, which is a stunning lake surrounded by tall Rocky Mountains, as well as hordes of tourists! If we asked this question to our friends – and maybe one happens to be an expert angler - we may receive different answers including secret lakes that have not yet been discovered by tourists or the best lake for fishing. Our friends can also consider our specific interests, suggest helpful resources (such as a lesser known forum on local fishing), and offer additional information about our query such as the best places on that lake to camp, where to fish on the lake, and what type of fishing gear to use. The point in this example is that there are different networks of information available to us, including formal networks of information organized on the internet and accessed by search engines as well as informal networks of individuals and experts who offer an additional strategy to connect us with the right data
Data are becoming increasingly easy to discover through the use of data repositories (Figure 4.1). Below we discuss the growing number (and centralization) of spatial data repositories, which can give access to academic, government non-governmental, international, and crowd-sourced datasets. Here we introduce each type of repository and offer some hints at what environmental data can be discovered in each.

Figure 4.1: Envisioning university and government data networks. Data within each network is concentrated within data repositories, yet considerable data remains ‘hidden’ among individual researchers and silos of the Ministry, but can potentially be accessed by finding the right connections. Sutherland, CC-BY-SA-4.0.
4.3 Data in Academia
Data librarians are particularly well-connected and trained to help you navigate these repositories and contacting them can be a good starting point in your search. Nonetheless, considerable data are not yet published. Some of these unpublished data have been analyzed in previous research and its existence could be discovered through a review of the academic literature. Other unpublished data remains essentially hidden, only known about by individuals or small clusters of individual researchers who created those data. In such a case, your only possibility to find such data are through a combination of asking around and reaching out to experts in the field. Once you know it exists, unpublished data could potentially be accessed through connecting with those researchers themselves, and requesting the data or inquiring about the possibility for a collaboration.
4.4 Government Data
Government data are also increasingly published in data repositories, specific to the level of government (Figure 4.1). There are multiple levels to government, including municipalities (the smallest), sometimes counties (precincts, townships, or parishes), provinces (or states), and nations (the largest), each of which often has its own data repository. Centralized repositories are becoming increasingly common and connect open data from all levels of Government. The Federated Research data repository is an aggregation of Canadian open data repositories, including municipal, provincial, and academic repositories. It includes a map-based search for datasets with location information tied to their metadata. In the US, geospatial data from federal, municipal, and state government repositories are being consolidated under Data.gov.
Because not all repositories are yet connected by a centralized repository, one must search in the correct repository. To do this, consider which government has jurisdiction over the specific subject area and geography of interest. For example, if you are interested in land use zoning and engineering features within a given city, this data are likely best provided by that individual city, either by finding it within a data repository or e-mailing the municipality with a data request. In Canada, the provinces have jurisdiction over most natural resources and thus provincial government data repositories tend to provide the best data coverage on natural resources such as, water, forests, wildlife, minerals, and topography. In British Columbia, for example, DataBC houses over a thousand datasets on natural resources, including forest inventory maps, natural disturbances, hunting statistics, administrative boundaries, and much more. Canada’s open data portal provides data on fish as well as environmental conditions (e.g., water quality, air quality, historical weather, etc.), which is under federal jurisdiction. Hydrological flow and water quality monitoring are readily accessible across Canada through the Hydat database, which can be easily accessed through the R package called TidyHydat (Albers (2017)).
Try using a web search to find the government open data pages for your city, province/state, and nation. What kinds of data can you find?
4.5 Census Data
This section introduces the census at a cursory level before launching into the applied question of how to find census data for your spatial analysis, using the Census of Canada as an example.
A census generally refers to a complete count by government of a specific region’s population and includes demographic attributes such as age, gender, language, income, and housing. Census data inform public policy, such as allocation of public funds, transportation network planning, and electoral area delineation. Census data also provide researchers with an opportunity to gain insight into the social and, to a lesser extent, environmental fabric of a country and are increasingly used in environmental and social-ecological research that aims to address social elements of environmental challenges (Tomscha et al. 2016) (Biggs et al. 2021). Censuses are typically conducted once every five years in Canada and every 10 years in the US.
In addition to demographics, many nations survey information related to economics or specific industries, such as agriculture. For example, Canada’s Census of Agriculture captures information on fertilizers, irrigation, livestock, farm types, and crop production across Canada. The Longform Census in Canada surveys additional questions but is only sent to a subset of the population, and the data are then used to estimate the attributes for the entire population.
A starting point to using census data in spatial analysis is to understand the geographic levels of census data, and then we address where the geography files and data can be downloaded.
4.6 Census of Canada Geographic Levels
To protect respondents’ confidentiality, the individual data collected during census enumeration is obscured from the public. Thus, census data can only be accessed by researchers in the form of statistics aggregated to varying geographic levels. Knowing these geographic levels is key to accessing census data and using them appropriately to answer your spatial questions.
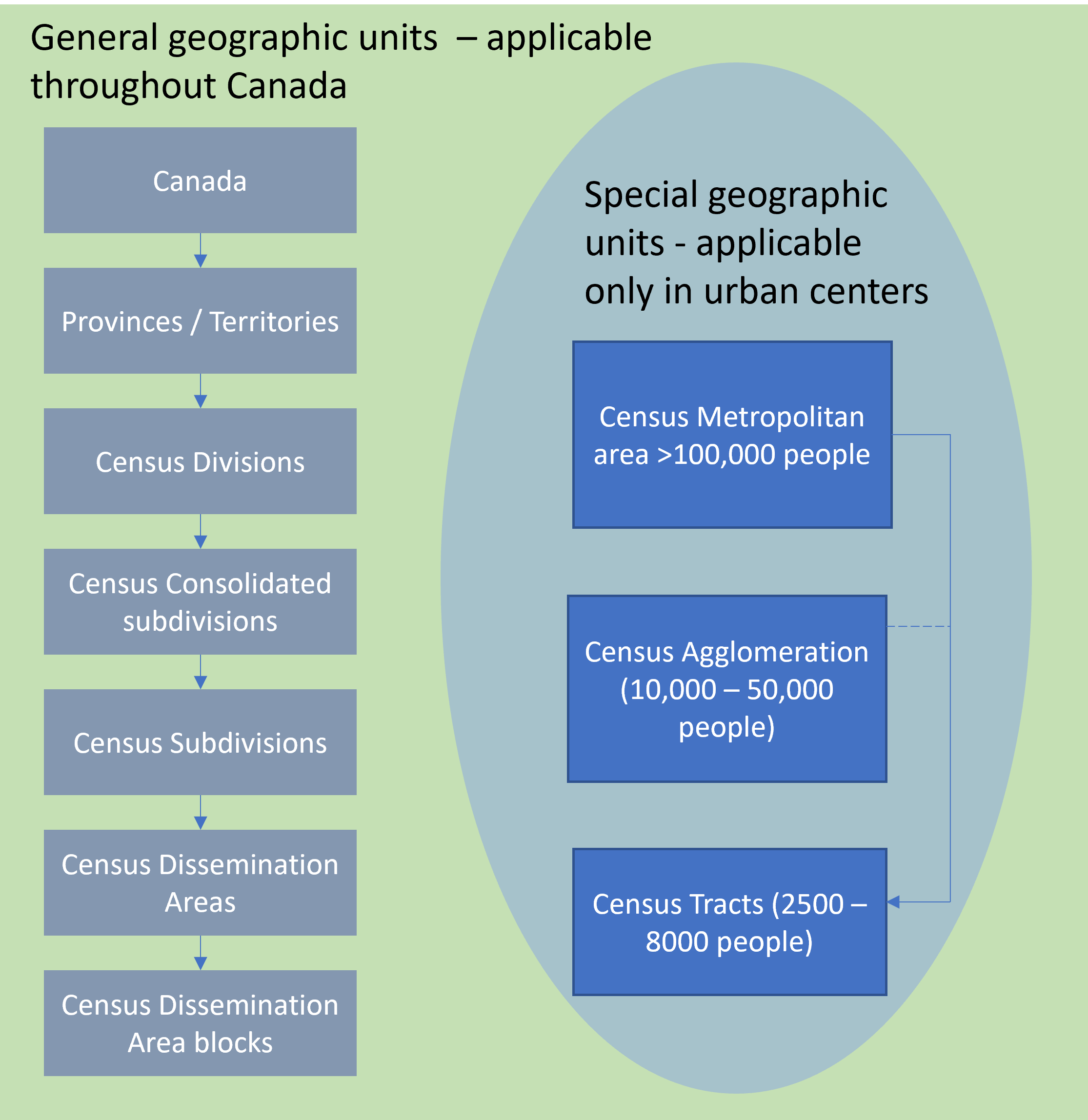
Figure 4.2: The geographic levels of the Census of Canada include general units (applicable everywhere throughout Canada) and also an additional layer for urban areas only. Sutherland, CC-BY-SA-4.0.
At the top of Figure 4.2 are Canada’s provinces and territories, which are then divided into census divisions, which in turn are divided into census subdivisions. Census subdivisions correspond to municipalities, but also include Indian reserves, and ‘unorganized areas.’ These three areas (municipalities, Indian reserves, and unorganized areas) are also aggregated into census consolidated subdivisions, which offer a more consistent geographic unit for mapping large areas as compared to subdivisions themselves. Census subdivisions are divided into dissemination areas, composed of one or more ‘dissemination area blocks’ (generally, a city block bounded by roads on all sides).
In addition to these general geographies, which apply throughout Canada, special geographic units are implemented as an additional layer of aggregation for urban centers. A Census Metropolitan Area (CMA) is a grouping of census subdivisions comprising a large urban area and its surroundings. To become a CMA, an area must register an urban core population of at least 100,000 at the previous census. A Census Agglomeration (CA) is a smaller version of a CMA in which the urban core population at the previous census was greater than 10,000 but less than 100,000. CMA and CA are useful for making comparisons across cities. CMAs and CAs with a population greater than 50,000 are subdivided into census tracts which have populations ranging from 2,500 to 8,000 and are intended to be relatively homogeneous in their demographic identity (i.e., a local neighbourhood).
Using census data for geographic analysis typically involves first identifying the smallest spatial unit at which the data are available. Recall that to protect the privacy of respondents, some data are only available at higher geographic levels. Another consideration is that if you plan to compile multiple census years, the geographic boundaries have typically changed over time in response to how the landscapes and information needs have changed. This creates substantial (though, not insurmountable) additional work that limits how the data can be used, especially for finer spatial scale analysis. An example of changes in the geography of census divisions is seen for British Columbia in Figure 4.3.

Figure 4.3: An example of how census boundaries have changed, showing changes in Census divisions for British Columbia from 1911 to 1986. Data from Clark (2016). Sutherland, CC-BY-SA-4.0.
4.7 Accessing Census Data
Statistics Canada maintains the geographic boundaries for the Census for each level in Canada. The Canadian Socio-economic Information Management System Statistics Canada data portal provides access to the Census of Canada as well as the Census of Agriculture, Aboriginal Peoples Survey, and other government statistical datasets. You have the option to search by a vector or an area of interest. Students with access to CHASS Canadian Census Analyzer (students of University of Toronto as well as many other subscribing universities) can use CHASS to access additional statistical data, which they can aggregate to census geographic units of their choosing.
Try this: Navigate to Canadian Socio-economic Information Management System Statistics Canada data portal and search a key word such as: “age.” A list of available geographic levels should be present on the left side, allowing you to check which geographic levels you would like to retrieve the data for. What geographic levels are present for age and which is the smallest geographic level (refer to Figure 4.3)? Now try searching the keyword: crop production. What is the smallest geographic level for crop production now?
4.8 Non-Governmental Organization Data
Many elements of the environment, such as biodiversity and large old trees, are not monitored by most governments. These knowledge gaps are sometimes filled by other organizations not associated with the government (i.e., non-governmental organizations) or by citizen science initiatives.
Pacific Salmon Foundation has collaborated with the help of First Nations and government to compile salmon information for BC so that the data can be readily viewed and downloaded for further analysis. Organizations such as the International Union for Conservation of Nature often synthesize and offer datasets that support their mandates such as monitoring species at risk and expanding protected areas.
Global Forest Watch specializes in monitoring forest cover across the planet. Canada was one of the original pilot countries for collecting early forest cover loss data. Global Forest Watch provides a number of data products and online web mapping applications on forest loss/gain, wildfire, land use, land cover, climate, and biodiversity that are readily available for analysis.
Ducks Unlimited provides maps of the Canadian Wetland Inventory and reports on future wetland loss, degradation, and restoration. Their website also includes online web mapping applications to interact with their datasets involving water fowl.
Do you know a non-governmental organization that is based in Canada or collects environmental data about Canada that should be highlighted here? Submit a request!
4.9 Citizen Science
Citizen science describes activities where members of the general public contribute information and data to help generate new knowledge and information (Lee, Lee, and Bell 2020). Citizen science has been used to fill in data gaps for widely distributed phenomenon that are otherwise difficult to gather. In addition to Open Street Map, which has created a free open geodatabase of the world, one of the most important examples is a collective global effort to map the distribution of global bird species using a mobile app known as E-bird, which has generated nearly 1 billion bird observations as of 2021. Likewise, alpine wildlife are difficult for researchers to observe and are costly to study owing to the effort and risk associated with accessing alpine areas, yet may be frequently spotted by mountain climbers who venture into alpine areas during their recreational pursuits (Jackson, Gergel, and Martin 2015). Citizen science is also used in fast-moving situations like natural disaster and to monitor long-term trends in the environment. For example, the British Columbia Big Tree Registry collates citizen science data on the locations of the largest trees in BC, thereby engaging citizens to help support policies to protect the largest trees in BC.
A useful starting point to check for citizen science datasets is Scistarter, which can be searched by keyword or location to identify citizen science projects around the globe. These datasets may be readily downloaded or downloaded through contacting the project leaders.
4.10 International Data
Some research questions extend beyond borders. For example, oceans are primarily international and data on oceans can be searched through the Ocean Biodiversity Information System. A database on food production and timber is published by the United Nations Food and Agricultural Organization. Research that attempts to address environmental problems at the global scale are often openly published online such as the global tree canopy height map (Potapov et al. 2021).
4.11 Metadata
Information has a lifecycle. After information is created, it might also be stored, published, distributed, reused, and retired. In each step of the way, some aspects of the information might become more important than others. For example, when publishing a journal article, the author may need to supply the contact information associated with their ORCID iD. In another case, someone using a GIS file downloaded from the internet would want to know what projection was used to create the file. As informationpasses through its lifecycle, whether it is a file, journal article, software, digital photograph, or any other system or data object, decisions are made about things like where to store it, who to share it with, and how to describe it. In order to reliably answer these questions, the object must also be accompanied by its own set of information. Metadata is the term we use to define “information about information”, and it describes your data so it can be used, shared, discovered, and understood by a wide audience.
When creating information, how do you know what to include in your metadata? Surely, you can’t be expected to predict what metadata will be needed in the future or what questions someone will ask about it. To help with this concern, many metadata schemas have been developed by different communities of practice which provide generally agreed upon guidelines for creating and maintaining metadata. Metadata standards are more universally endorsed than metadata schemas, and therefore come with a larger base of support. One of the most widely endorsed metadata standards for geospatial metadata–the Federal Geographic Data Committee’s (FGDC) Content Standard for Digital Geospatial Metadata–has an abundance of resources online for learning more about the standard, including a tool from the U.S. Geological Survey called Metadata in Plain Language.
In addition to resources for humans to learn more, standards provide a means for machines to transform or convert metadata from one format to another so that new systems can accurately and efficiently interpret metadata, like converting into HTML so that it can be more human-readable in a web browser.
It is said that “metadata is a love note to the future”. You may not see the importance at first, or know exactly what to include in your metadata, but inevitably you will find out once you hand in your project files, publish a research paper, or share your data with your supervisor. Creating metadata might at first seem tedious, but it will make your own data more reproducible, shareable, and impactful.
4.12 Creating Metadata
Luckily, many common software and applications have built-in features for users to easily (sometimes automatically) create, edit, and transform metadata–freeing practitioners from some of these tedious and time-consuming tasks. It is always advisable to investigate this at the start of a project so that any extensions or project files are configured to ensure they’re working correctly. You might also find yourself bouncing from software to software and file to file when working with digital objects or files which can complicate the processes involved with keeping good metadata. In these cases, you might need to rely on your own documentation to help assemble metadata in the future by maintaining a notes file, using code annotations, or other techniques for logging all of the important steps involved so that others can and recreate your work.
When thinking about the types of information that you might want to include in your metadata, consider these four general categories of metadata:
Descriptive metadata – This type of metadata provides all the necessary information describing your data or study, including how it was derived and uncertainty errors. For example the data’s abstract, methodology, file attribute descriptions, purpose, uncertainty errors, and access information.
Technical metadata – This type of metadata provides technical and configuration information about your study or data, and is very discipline-specific. Geospatial metadata might include things like CRS / projection / datum used, attribute data types, software used, and character encoding.
Discovery metadata – Discovery metadata is used to index and link your data with other information. When you search and filter information by subject, date, or filename, you’re using discovery metadata. This could include things like, title, date, keywords, or geographic extent.
Administrative metadata – This type of metadata reflects the ownership and terms of use information about a study or data, including copyright, contact info, version, and update status.
As you begin a project’s metadata creation starts with investigating industry or discipline standards for your topic to find out what metadata standard or schema is most widely recognized. Consider the software you’ll use to work with and process your data, and find out what kinds of built-in tools or features it might have available to help with generating metadata. You may find that others before you have figured out good approaches to metadata creation that can be adopted for use in your own project.
At the very least, one great way to start documenting your project or data is by creating a README file. A README file is a text-based file (.txt or .md) that explains your project clearly and concisely so that others know what it is and how to use it. README files are stored alongside all of your other files being used for your project or study, usually in the top-level file directory so that it is easily found. These descriptive files are also a great way to link to other material that is contained within your file directory or elsewhere on the web. If you’re just starting out, you’ll find many resources on the web for guidelines and best practices for creating READMEs, including UBC’s Creating a README for your dataset Quick Guide which includes a README template in the .txt format.
4.13 Unpublished Data and the Data Request
Governments manage a wide variety of data, which is sometimes located out of public sight. Datasets that are not readily accessible online, may still exist and can potentially be retrieved through a data request to the appropriate government agency. In the spirit of open data, many governments are becoming increasingly responsive to data requests, but success of this approach often hinges on knowing what to request and who to make the request to.
Accessing data that are not readily available adds extra challenge but can reward you with new research and networking opportunities that can be highly beneficial for both parties. Since these data are not immediately available to everyone, one benefit to researchers is the novelty of analysis that can be applied. The data provider may also benefit from the knowledge gained by your research. They may be able to assist you with understanding the data, disseminating the final report, and even connecting you with job opportunities and other ways to continue your skill development. When sending a data request or data query, always be respectful of their time, and be tactful. A data request template is provided below:
Dear ... (person, or institution)
State your name and affiliation (e.g., university department and program/supervisor)
Briefly state your intended research or research aspiration (1-2 sentences)
State your **data inquiry** (e.g., do you know if x data exists?) or **data request** in bold text. Although you may not know exactly what you are looking for, try to be as specific as possible on the type of data you are requesting by describing. Give your geographical area of interest if known either descriptively, in a map, or as a shapefile.]
Thank them for considering your request. 4.14 Historical Data Collections
Historical data collections generally include any spatial data source excluding satellite-based remote sensing that was produced prior to the widespread commercialization of GIS in the mid 1990’s. Historical data are typically not available as ready-to-use digital layers, and thus work is required up front to digitize these data in preparation for spatial analysis.
Historical datasets can be extremely valuable in environmental research because they extend our ability to observe how the environment has changed over longer time horizons, potentially revealing vastly different landscapes and environmental conditions from those seen today. This insight can help remind us of levels of degradation or abundance that have become ‘forgotten’ by today’s environmental managers, and can lead to surprising discoveries (McClenachan et al. 2015).
Although historical datasets can be very useful, they were often not collected for the intended purpose of being analyzed by future researchers. Data were often collected to serve the needs of the day, and were collected in a cost effective manner using tools and science that were available at that time. While this is not usually an issue for Census data, which has used relatively consistent survey questions through time, it complicates use of other datasets such as historical forest inventories, which have evolved their methods in step with technology and changing perceptions of how the forest ought to be monitored and valued. Thus, knowledge of how historical data were collected is sometimes required to accurately understand and interpret it. Overall, the process of locating, digitizing, and interpreting historical data can be a substantial portion of the work in a historical spatial analysis. In this section we cover historical aerial photograph collections, historical natural resource administrative data as well as historical maps.
4.14.1 Historical Aerial Photographs
The advent of aerial photographs, which are photographs of the Earth’s surface taken from above (generally from an airplane), greatly improved mapping beginning in the 1930’s and became the primary source of data for mapping land cover, timber volumes, topography, and national defense planning. Today, they offer a valuable tool for the unique spatial and temporal resolutions they offer. Temporally, aerial photos offer snapshots of landscapes that predate satellite-based remotely-sensed data by many decades (Morgan et al. 2017), which can help inform restoration targets and cumulative effects assessments (Harker et al. 2021). Aerial photos vary in their spatial resolution, but sometimes offer a surprisingly high spatial resolution that can be used to study fine-scale landscape attributes and their changes, such as stream courses (Little, Richardson, and Alila 2013), fish habitat (M. J. Tomlinson et al. 2011), and soil hydrodynamics (Harker et al. 2021).
Using aerial photographs to track landscape change often requires first ‘tying’ them to the Earth to produce and orthophoto. An orthophoto is an aerial photograph or satellite imagery geometrically corrected so that the scale is uniform, such as in Figure 4.4. Unlike orthophoto, the scale of ordinary aerial images varies across the image, due to the changing elevation of the terrain surface (among other things). The process of creating an orthophoto from an ordinary aerial image is called orthorectification. Photogrammetrists are the professionals who specialize in creating orthorectified aerial imagery, and in compiling geometrically-accurate vector data from aerial images.
Compare the map and photograph below. Both show the same gas pipeline, which passes through hilly terrain. Note the deformation of the pipeline route in the photo relative to the shape of the route on the topographic map. Only the topographic map is accurate here. The deformation in the photo is caused by relief displacement. The photo would not serve well on its own as a source for topographic mapping.

Figure 4.4: Example of how a linear feature can appear crooked in an aerial photograph that has not yet been orthorectified due to relief displacement. DiBiase (2014), CC-BY-4.0.
Even in their un-orthorectified state, historical aerial photos can offer a powerful communication tool. They offer a window into historical landscapes that can be easily discerned and appreciated by viewers. Thus, even without orthorectification and performing spatial analysis, historical aerial photos can enrich a research report and other communications.
4.14.2 Accessing Historical Aerial Photograph Collections
Aerial photography missions involved capturing sequences of overlapping images along parallel flight paths. A flight path produces a “roll” of numerous adjacent images that overlap. Flight paths tend to be here and there, but not necessarily exactly where you need them! Therefore, the first step is to determine the availability of historical photographs rolls for your time frame and area of interest. Some collections can be searched relatively easily using a web-based GIS. For example, the Canada National Air Photo Library has a collection of roughly 6 million aerial photos some dating back to the 1920’s, which can be searched using the Earth Observation Data Management System. A search generally follows these steps:
- Determine your area of interest.
- Decide on the time-frame of interest.
- Search via a GIS web map or paper flight line maps and examine which flight rolls cross over your time frame and area of interest.

Figure 4.5: Example showing the availabiltiy of historical aerial photos in eastern Newfoundland at three time steps. Data from Natural Resources Canada (n.d.a), Open Government License - Canada.
Figure 4.5 shows the results from an example search. In this example, the area of interest (large pink rectangle, figure 4.5 was set by navigating to the study site within the web map then setting the current extent as the area of interest. Here the extent is centered on the coastline between St. John’s, Newfoundland and Cape Spear, the most easterly point in North America. We then searched for **aerial photographs at three different time frames: 1940-1945 (Figure 4.5 A, 1950-1955 Figure 4.5 B, and 1960-1965 Figure 4.5 C). Indeed, aerial photos were found to be available at each period. The photos with smaller boxes (or foot prints) tend to have higher spatial resolution but cover less area. Assuming that fine spatial resolution is desired, the smallest photos have been selected in this example and could then be requested from the library. Previews are often not available so we will not fully know the quality of the photos until we inspect them.
Go to the Canada Eartch Observation Data Management System and search for historical aerial photos in your chosen area of interest using the time frames 1935-1950 and then 1950-1980. What is the oldest photo available?
If you searched but did not find anything helpful, do not be discouraged. The area of interest in the example of Cape Spear, Newfoundland, happens to be a strategic location for national defense so it not surprising that it has excellent coverage in the National Air Photo Library. In contrast, if you are interested in seeing an environmental feature such as historical forest cover in northern BC, recall that natural resources fall under the jurisdiction of provinces in Canada. Consequently, provinces may house aerial photo collections for your area. Some of these collections have been preserved by government or other institutions, such as the Geographic Information Center (GIC) at the University of British Columbia, which rescued a collection of 2.5 million aerial photos. These photos are available for researchers and commercial use. The GIC also maintains a list of other aerial photograph libraries, including for Alberta, Yukon, and the United States.
4.15 Natural Resource Administrative Data
Governments often conduct ecological and economic monitoring in their efforts to inform public policy and environmental management. Herein, these data are referred collectively to as natural resource administrative data. These data include information collected during the process of administering natural resources use, such as to calculate fees, royalties, and licensing payments that the resource users must pay to the government for the use of public natural resources. Administering natural resources also requires monitoring data to spatially allocate harvest quotas on resources such as fish, big game, and timber. As opposed to remotely sensed data, these data often describe the actual amounts of natural resources available or used, and sometimes the number of users, who the users are, and their subsistence and dependence on the resources.
These data often come in a form called spatial panel data. Spatial panel data describe time series associated with particular spatial units (e.g., cities, wildlife management units, timber harvesting areas). Using spatial panel data typically requires:
- Downloading (or digitizing, if necessary) the statistical data as a spreadsheet
- Downloading the spatial geometry file
- Linking the two files using an attribute join
An example of a marvelous and yet relatively easy to use natural resource administrative data record is the BC big Game Hunting Statistics, which documents the number of large game hunted in BC by species, by hunter type (BC resident vs. non-resident hunter), and the effort (number of days) that went into the hunts. These data can be made spatial by performing an attribute join with the BC Wildlife Management Units Layer. Attribute joins are discussed in Chapter 5.
Many natural resource administrative records are in digital form back to about 1980. Before that data often only exists in archival documents and must be digitized. Libraries are actively digitizing important archives, such as government annual reports, which are a rich source for natural resource administrative data.
4.16 Historical Maps
People have collected spatial information and mapped the world since long before GIS or aerial photos existed. Efforts are underway to preserve and digitize historical maps, and some collections are readily accessible. For example, insurance maps are maps made by insurance companies who mapped buildings, industrial complexes, and neighbourhoods to administer insurance policies since the late 1800’s (e.g., for British Columbia). Forest cover mapping became common in the early to mid 1900’s (though, the early maps rarely survived) to estimate timber volumes. Natural disturbance mapping also became widespread in the early 1900’s and considerable work has already been done to digitize and turn those data into readily usable forms (e.g., for wildfire and insect disturbance in British Columbia). Land surveys dating back to the mid 1850’s have also been used to systematically map historical forest cover, land ownership, and linear features such as roads (Tomscha et al. 2016).
Geographers recognize that all maps are subjective and historical maps are thus sometimes studied to understand how historical landscapes were perceived by cartographers, revealing potential social biases and political orientations of those who commissioned or created the map. This treads into the social sciences and humanities disciplines, which can offer additional and important ways to understand land management challenges today. For example, historical geographers have studied the history of fur trapline mapping because it offers insight into how First Nations traditional territories were ascribed into a form of information that could fit with the worldview of colonial governments (Iceton 2019). Thus understanding the transcription of these areas into maps that happened a century ago may help inform the complex spatial problem of how First Nations rights and titles to their traditional territories can be addressed in treaty negotiations and reconciliation.
4.17 Georeferencing Historical Maps
Although many types of data seem to be georeferenced, other information must be first processed into a form that can be analyzed. This is especially true for any data captured prior to when Global Navigation Satellite Systems (GNSS) became commercially available in the 2000’s. For example, decades and sometimes centuries of data exist in the form of herbaria, ship logs, and tree ring records that offer salient information on the spatial distribution of biodiversity and natural processes. This information cannot readily be brought into a GIS. The solution is georeferencing, which is a process to assign non-spatial information a spatial location (x and y coordinates) based on a coordinate system. Here we discuss georeferencing as it applies to historical maps. To supplement this section, general theory is provided about georeferencing aerial images in Chapter 13.
A common use case for georeferencing in landscape studies is when an historical map must be brought into GIS and overlaid with other data. Imagine you have a paper map and you use a desktop scanning device to scan it and save it as a digital image. This map depicts a particular area on Earth but there is no way for your computer to know where and how on Earth to place this map (figure 4.6). In order to solve this problem, it is necessary to assign it geographic coordinate information so that GIS software can correctly align it with other georeferenced data.

Figure 4.6: The need for georeferencing illustrated conceptually. Adapted from University of Texas Libraries (2021). CC-BY-NC-2.0.
Georeferencing is typically carried out using GIS software. The process of georeferencing varies slightly based on the GIS software you are using and the characteristics of the raster data you are working with, but the case study below provides a generalized workflow to help learn the overall process. Two important aspects are placing control points and rubbersheeting.
Control points are the locations on the map that we will use to tie our historical map into a coordinate system. Control points should be spaced evenly across the the map. There must be at least 3 control points, but preferably more than 10. Control points should be spaced relatively evenly to obtain a good rendering. Two options are discussed below for control points
4.17.1 Control Points on Maps with Grids or Graticule
Large area maps (e.g., an entire country or province) typically have a graticule, which depicts lines of latitude and longitude, and smaller scale maps often have UTM (Universal Transverse Mercator) grids (see Chapter 2 for more on map coordinate systems). These grids or graticules may span across the map or just be located along the corner or edges of a map. Such maps can often be georeferenced in a GIS by first setting the desired coordinate system and then toggling on the grid or graticule within the GIS. Control points can be placed on the scanned raster at the line intersections than tied to the grid toggled on in the GIS.

Figure 4.7: A comparison of (A) an historical census map from 1931 with no graticule versus (B) a 1961 census map with graticule representing latitude and longitude. Panel C shows a close-up of the coordinate detail. Sutherland, CC-BY-SA-4.0.
4.17.2 Grid and Graticule as Control Points
Not all maps have geographic coordinates on the map or along its corners (Figure 4.7 A). For such maps, control points must be placed on geographic features that can be linked to a base map that is already georeferenced and shows the locations of these features. Geographic features should be stable over time. For example, an ideal geographic feature is an island or cape in the ocean or a mountain top. Be aware that many features do change over time: rivers meander, lake shores change shape from flooding and drought, glaciers melt and recede, coastal beaches change with tides and sea level rise, and vegetation can migrate or disappear over time. In urban areas, try to identify features that have not changed over time. If using roads, use the center of road intersections. Avoid using roofs of buildings because these can be distorted by an image phenomenon called relief displacement where tall features will appear to “lean” away from the focal point of the centre of the image and thereby bias your georeferencing strategy. If you must use buildings, ensure you are using the visible corners where the building meets the ground level. For the same reason, you should avoid using any tall features as control points (e.g., trees, light poles, sign posts). You want to stay as low to the ground (datum) as possible to achieve an accurate georeferenced map.
4.17.3 Rubbersheeting
Once the control points are set, a transformation is applied to mold the historical map as best as possible into a map coordinate system. The practice of georeferencing historical maps using control points and transformations is an example of rubbersheeting. In cartography, rubbersheeting refers to the process by which a layer is distorted to allow it to be seamlessly joined to an adjacent geographic layer of matching imagery. This is sometimes referred to as image-to-vector conflation. Often this has to be done when layers created from adjacent map sheets are joined together. Rubbersheeting is necessary because the imagery and the vector data will rarely match up correctly due to various reasons, such as the angle at which the image was taken, the curvature of the surface of Earth, minor movements in the imaging platform (such as a satellite or aircraft), and other errors in the imagery. A variety of transformations can be used during rubber sheeting. You should test a few to see how they work then choose one, which appears to produce the most satisfactory results in terms of the visual fit and lowest amount of error. If you are rubbersheeting multiple maps, it may be beneficial to use a consistent transformation to facilitate writing up your methods and communicating your research.
4.17.4 Documenting Georeferencing
During the process of georeferencing you must document the number of control points and the root mean square error (RMSE). Although there are multiple sources of uncertainty in the spatial precision of a historical map, uncertainty should be characterized where possible to demonstrate rigour in your methods and for communicating uncertainty.
4.18 Summary
Data are becoming increasingly accessible thanks to the open data movement, but one must still need to know where to find it. The search for data, whether social, environmental, or economic in nature, is facilitated by data repositories as well as informal approaches such as networking with colleagues, consulting data librarians, and reaching out to experts in your subject area. When data does not exist, we can sometimes create it. Historical data such as aerial photos, natural resource administrative data, and historical maps must often by digitized into a form useable for spatial analysis. However, this effort can be worth while for researchers interested in history and for the unique information gained on social and ecological change.
4.19 Reflection Questions
- What are the key levels of Government where you live, and what kind of spatial data might each one manage?
- What are two ways to find unpublished spatial data that is owned by a researcher?
- What are the different types of data repositories where you can access spatial information?
- If you were to start a citizen science project to capture environmental data to inform public policy, what kind of information would you try to capture?